2006年Google发表了BigTable论文,推动了LSM存储架构的流行。LSM(Log Structured Merge-Tree)是一种数据组织形式,大多数的NoSQL都是基于LSM架构实现的。由于区块链系统基本上使用像Level DB之类的NoSQL数据库,因此,本文将对LSM的概念、原理和操作进行介绍。
背景
传统关系型数据库采用B树或者B+树作为数据存储结构,从而进行高效查找。但这种存储模式保存着磁盘时会有一个明显的缺陷,即逻辑上很近的块在物理磁盘可能很远,这就会产生大量的随机读写。对磁盘来说,随机读写比顺序读写速度慢的多,为了提高性能,需要将对磁盘的随机操作转换为顺序操作。而LSM的产生就是为了这个目的,将随机写转化为顺序写,从而大幅提高写性能,但也牺牲了一些读性能。
LSM原理
LSM的实现原理大致如下:
- 当有写操作时,写入位于内存的buffer,内存中通过某种数据结构(如红黑树、map、skiplist)保持key有序;一般实现也会将数据追加写到磁盘Log文件,以备必要时恢复。
- 内存中的数据定时或按固定大小地刷到磁盘文件(sstable)。更新操作只不断地写到内存,并不更新磁盘上已有的文件。
- 随着数据越写越多,磁盘文件也越写越多,这些文件变的不可写且有序。
- 定时对文件进行compaction操作,消除冗余数据,减少文件数量。
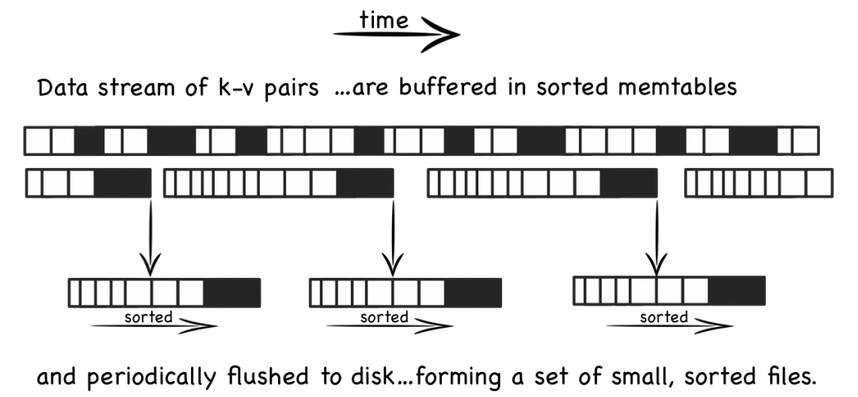
从上面的实现原理可以看出,LSM的写操作只更新内存,而内存中的数据以数据块的形式刷到磁盘,这个过程是顺序磁盘IO操作;另外,磁盘文件也会定期进行compaction操作,这个过程也涉及磁盘IO操作。
LSM的读操作先从内存进行访问,如果内存访问不到,再逆序从磁盘文件中进行查找。由于磁盘文件本身是有序的,且定期的compaction操作减少了文件数量,因此查找过程相对较快。
LSM Compaction
Compaction是LSM实现中重要的一步。写数据时由于较旧的文件并不会被更新,重复的记录只会通过创建新的记录来覆盖,因此会产生很多冗余数据,而Compaction操作就是用来消除这些冗余数据,同时也能减少文件数量。
按文件大小的Compaction:当一定数量的sstable文件被创建,例如有5个sstable,每一个有10行,他们被合并为一个50行的文件(或者更少的行数)。这个过程一 直持续着,当更多的有10行的sstable文件被创建,当产生5个文件时,它们就被合并到50行的文件。最终会有5个50行的文件,这时会将这5个50行的文件合并成一个250行的文件。这个过程不停的创建更大的文件。这种方式有个问题就是大量的文件被创建,在最坏的情况下所有文件都要被搜索。
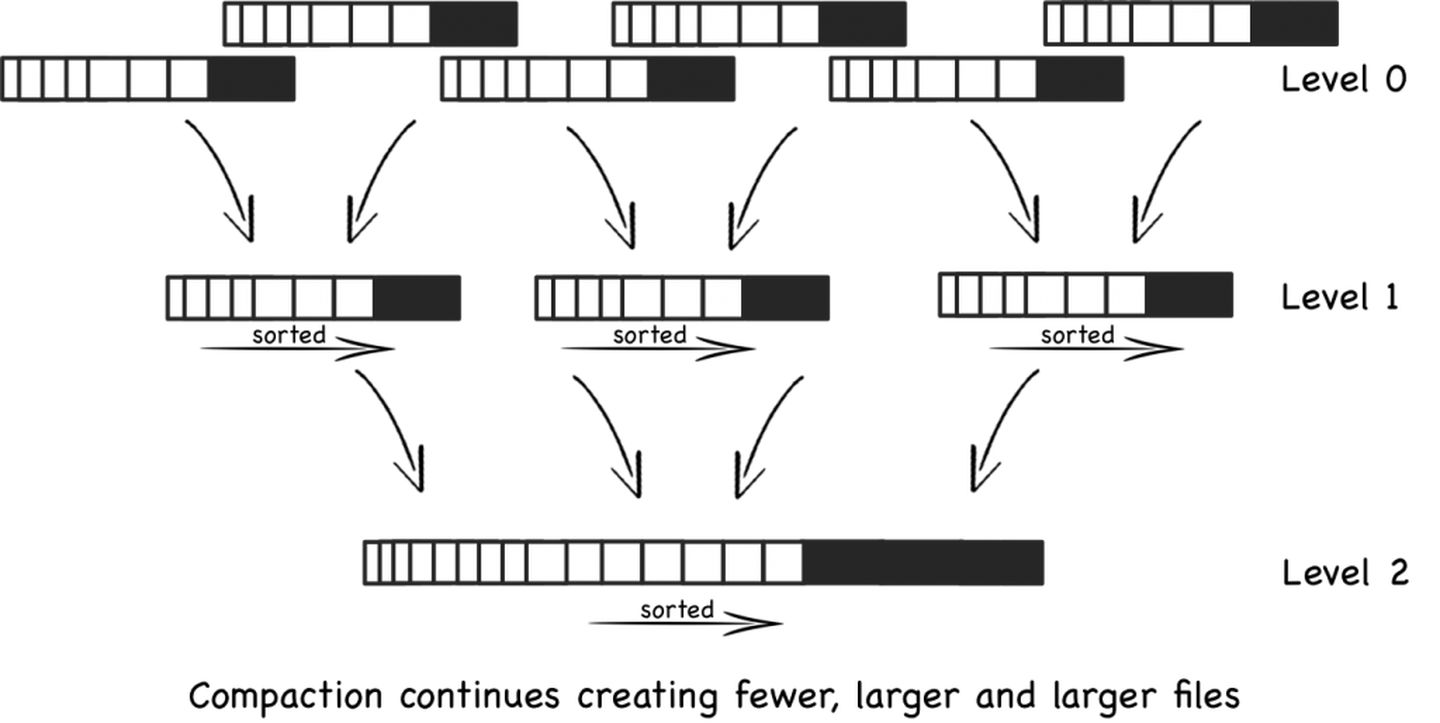
Levelled Compaction:而Level DB、Cassandra等NoSQL中,使用了基于层级的Compaction方案(Levelled Compaction),而不是根据固定文件大小进行Compaction,即生成第N层时,采用第N-1层的数据进行排序合并,使得每层的数据文件都是有序的。另外,每一层可以维护指定的文件个数,同时保证不让key重叠,也就是说把key分区到不同的文件,因此在一层查找一个key,只用查找一个文件。但在第一层,由于不断有数据文件产生,只能保证文件内的数据有序。
读优化
当一个读操作请求时,系统首先检查内存数据(memtable),如果没有找到这个key,就会逆序的一个一个检查sstable文件,直到key 被找到。因为每个sstable都是有序的,所以查找比较高效(O(logN)),但是读操作会变的越来越慢随着sstable的个数增加,因为每一个 sstable都要被检查。假如K为sstable个数, N 为sstable平均大小,查找的复杂度是O(K log N)。因此,LSM的读操作比采用本地更新的结构要慢。
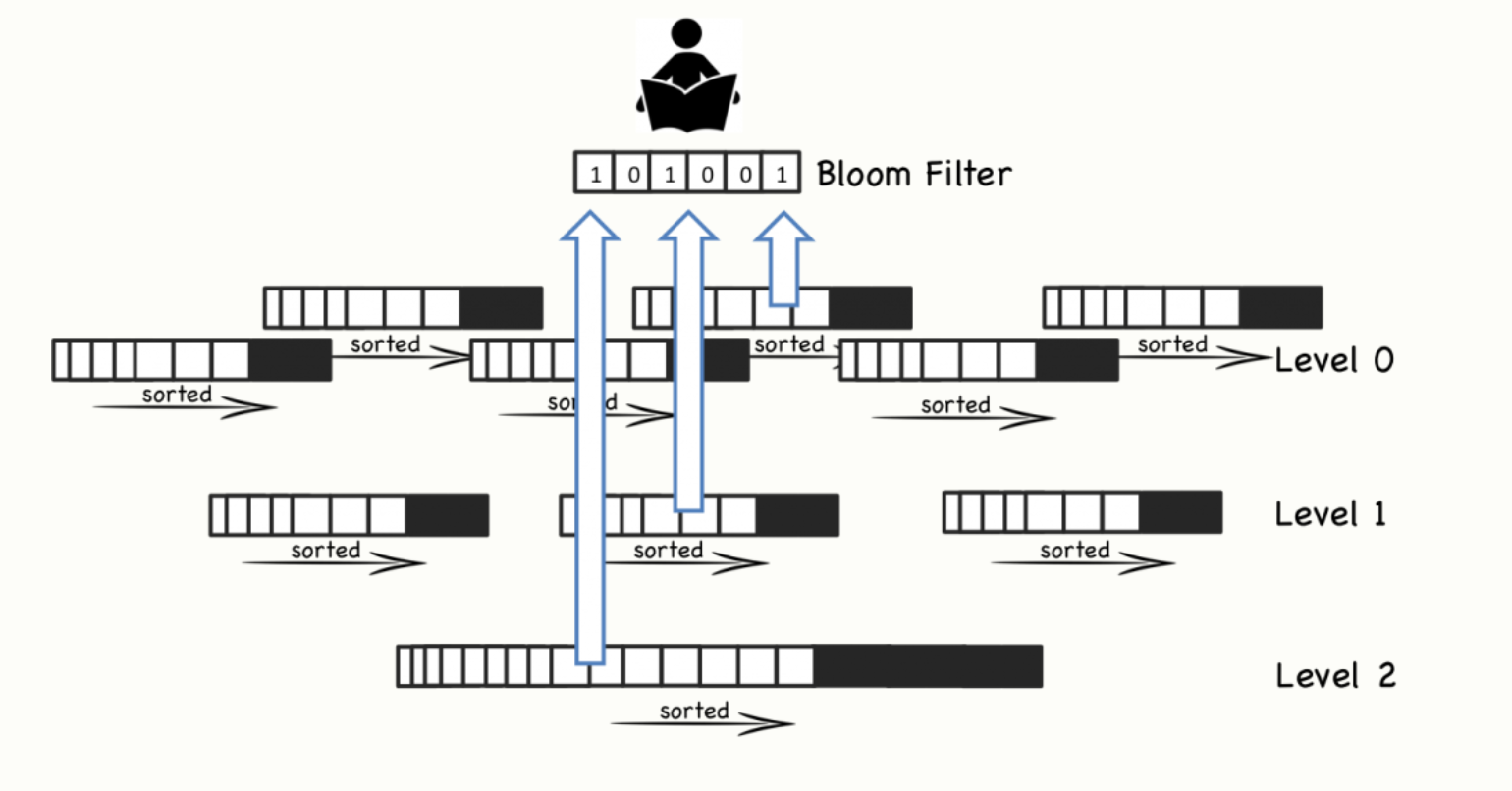
页缓存:可以采用一些技巧提高读性能,最基本的方法是页缓存到内存中,以减少二分查找的时间。对LevelDB来说即TableCache,即将sstable按照LRU算法缓存到内存中。LevelDB和BigTable是将 block-index 保存在文件尾部,这样查找就只要一次IO操作,如果block-index在内存中。一些其它的系统则实现了更复杂的索引方法。
布隆过滤器:即使有每个文件的索引,随着文件个数增多,读操作仍然很慢。通过周期的合并文件,来保持文件的个数,因些读操作的性能在可接收的范围内。即便有了合并操作,读操作仍然会访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作,布隆过滤器是一种高效的方法来判断一个sstable中是否包含一个特定的key。
总结
LSM通过管理一组索引文件,而不是单一的索引文件,将随机IO转换为顺序IO,从而提高了写性能,而代价是读操作需要处理大量的索引文件。
LSM的原理与区块链的块数据和状态数据处理模式很相似,因此区块链很适合使用LSM实现的NoSQL数据库(如LevelDB)进行数据存储。